


闪迪正在推动一场存储架构的根本性重构——将计算单元与NAND闪存直接键合,并将HBM的角色从核心内存降级为辅助层级。
据美国专利商标局公开的专利文件,闪迪提出了一种将多核处理器直接集成于CBA存储芯片之上的3D堆叠架构,整体封装于同一中介层之上,HBM则围绕该堆叠结构分布于周侧。这一设计意在同时突破HBM容量天花板与现有高带宽闪存(HBF)架构在延迟、功耗及系统集成层面的局限。
该专利的曝光表明,闪迪在加速推进HBF量产路线的同时,已在专利层面布局更激进的存储-计算融合方案,对AI加速器及GPU的内存架构设计路径具有潜在的深远影响。
HBM容量瓶颈催生新架构探索
HBM凭借高带宽优势成为当前AI芯片的主流内存方案,但其容量限制日益成为制约因素。据科技媒体Wccftech报道,现有HBM解决方案单栈容量通常为32至64GB,难以满足大规模AI模型对内存容量的持续增长需求。
为此,闪迪此前已推出HBF架构,借鉴HBM的垂直堆叠理念,通过硅通孔(TSV)将多层NAND闪存互联,形成统一存储栈。据闪迪披露,HBF单栈容量可扩展至4TB,在带宽上接近HBM水平,同等成本下容量可达HBM的8至16倍。
然而,NAND闪存在容量优势之外仍存在固有短板。Wccftech指出,NAND在系统架构中距离计算核心较远,数据访问速度慢于基于DRAM的架构,这一结构性劣势限制了HBF在延迟敏感型工作负载中的适用性。
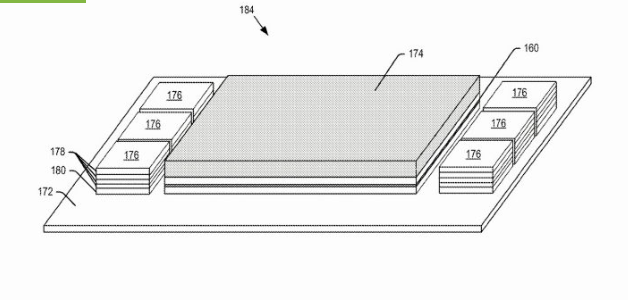
新专利核心:计算与NAND直接键合
闪迪最新专利提出的方案,正是针对上述延迟问题的直接回应。根据专利文件,该设计将一块基于CBA结构构建的NAND闪存芯片置于计算芯片(如AI加速器或GPU)正下方,实现处理器与NAND的直接物理键合。
CBA结构本身将大容量NAND闪存阵列与CMOS逻辑层合二为一,而整个集成堆叠随后被安装于中介层之上。HBM芯片栈则附着于该组合堆叠的一侧或多侧,与NAND层共享同一中介层平台。
这一架构的关键在于重新定义了各类存储介质的分工边界:HBM负责处理即时性、高速内存操作,而NAND闪存层则承担读写密集型工作负载及大规模数据存储任务。据Wccftech报道,在此配置下,HBM仍被集成于系统之中,但其角色已从主导地位转变为整体存储-计算层级中的特定功能模块。
HBF之外的并行布局
值得关注的是,上述专利所呈现的架构方向与闪迪现阶段主推的HBF路线并非替代关系,而是并行推进的技术储备。闪迪目前仍在加速HBF的开发进程,HBF代表着其在近期可落地的高容量存储方案上的主要商业押注。
新专利所描述的处理器直接键合NAND的3D堆叠方案,则指向更长期的架构演进路径,旨在从根本上缩短计算单元与大容量存储之间的物理距离,从而在系统层面同时优化带宽、延迟与能效表现。
对于AI芯片设计商及封装技术供应链而言,闪迪此次专利布局释放出明确信号:存储与计算的深度融合正从概念走向具体技术路径,围绕中介层封装平台的生态竞争或将进一步加剧。
本资讯中除公开信息外的其他数据均是基于公开信息(包括但不仅限于行业新闻、研讨会、展览会、企业财报、券商报告、国家统计局数据、海关进出口数据、各大协会和机构公布的各类数据等等),并依托废废网/道奇财经内部数据库模型,由研究小组进行综合分析和合理推断得出,仅供参考,不构成决策建议,客户决策应自主判断,与废废网/道奇财经无关。
废废网/道奇财经对本声明条款拥有最终解释权,并保留根据实际情况对声明内容进行调整和修改的权利。





